DeepSeek 大模型的应用(四)
4.大模型的应用
一、关于“落地应用”的总体说明
- 主讲人认为这部分变化非常快,不是今天最核心的内容
- 但提示词技巧部分在网络上很流行(被误传为“北大出的 PPT”),实用性很强
- 重点在于:提示词技巧会随着模型智能的提升而逐渐变得不重要(模型越聪明,越不需要复杂的提示词)
二、提示词核心原则(针对推理模型,如 DeepSeek R1)
1. 把 AI 当人看
- 要与 AI 沟通,而不是“命令”
- 提示词的目的是:说一句 AI 能听懂的话
- 类比:模型智能还不够强时,需要像训练狗一样用它能懂的语言;智能足够强时,随便说人话它就能懂
2. 清晰表达
- 越含糊,模型理解越差
- 直接告诉模型你要什么结果,而不是教它怎么做
3. 通用公式(适用于推理模型)
我要干什么 + 给谁用 + 希望达到什么效果 + 担心什么问题
把这四点说清楚就够了,不要给详细步骤。
三、关键对比:生成模型 vs 推理模型的提示词差异(重点!)
| 对比项 | 生成模型(传统,如 GPT-4o) | 推理模型(如 DeepSeek R1) |
|---|---|---|
| 沟通方式 | 需要教它“怎么做” | 只需告诉“要什么” |
| 详细步骤 | 需要给出(第一步、第二步、第三步) | 不要给,会干扰它,反而不如它自己规划 |
| 人格化比喻 | 像不太懂事但能干的小孩,需要教 | 像同伴,有时候比你还清楚该怎么干 |
过去用生成模型,提示词模板通常是:“你是 XX 角色,你要做 XX,第一步 XX,第二步 XX……”
现在用推理模型,直接说:“我需要 XX 结果,给 XX 用,希望达到 XX 效果,担心 XX 问题。”
四、提示词的几个重要注意事项
1. 提示词与模型强相关
2. 小心 Token 消耗(算力成本)
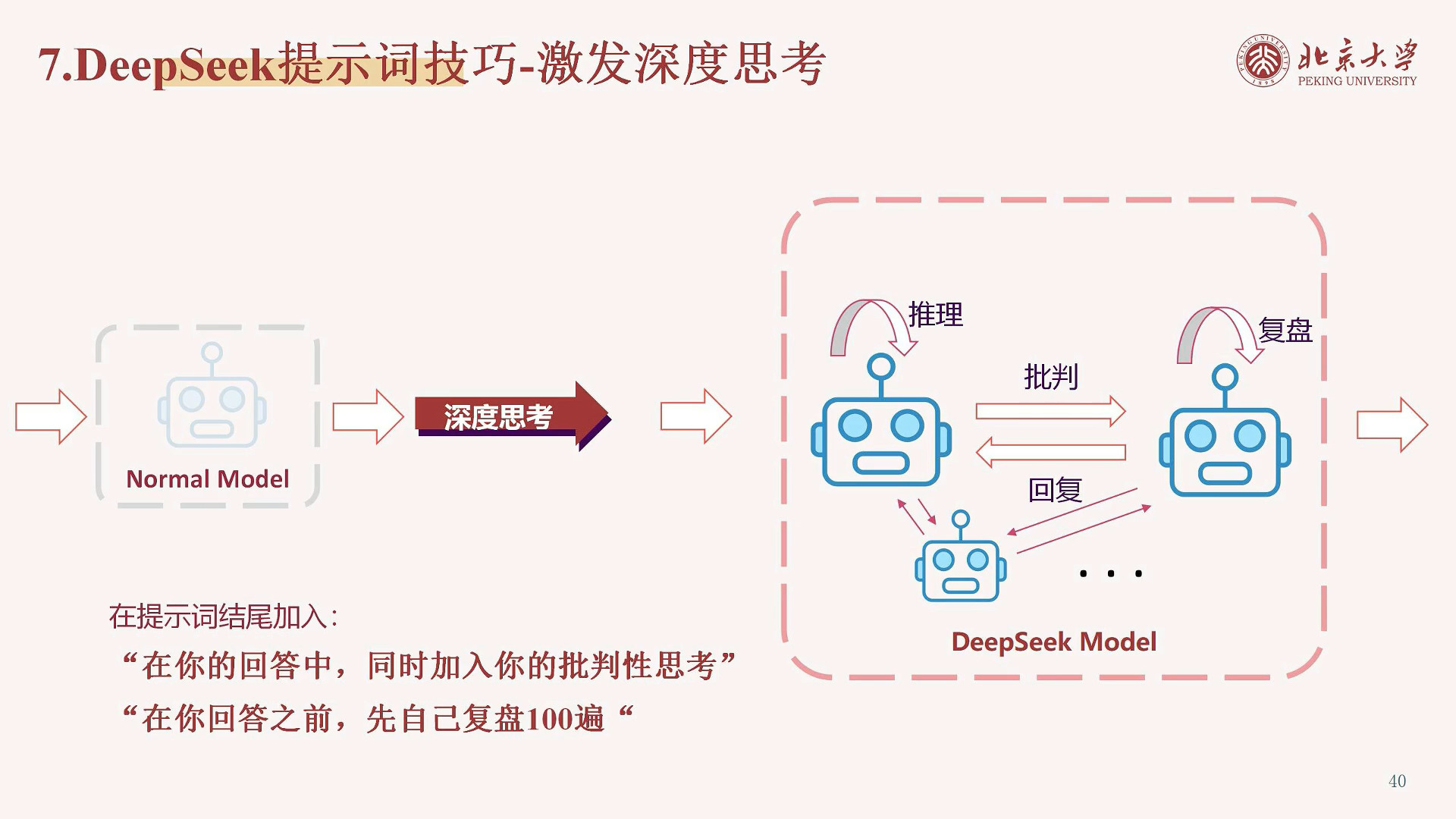
- 像“在回答之前先自己复盘 100 遍”这类提示词,会大量消耗 token,增加成本
3. 厂商建议 vs 用户经验
- 厂商(如 DeepSeek、OpenAI)会给一些提示词建议,来自工程师的测试
- 但用户的实践经验往往更好,因为真实场景更多样
五、应用场景举例(重点:教育/学术领域)
1. 学术论文写作
OpenAI 和 DeepSeek 都推出了 “Research” 能力
论文写作的套路感太强,非常适合大模型:
- 文献综述
- 资料检索
- 数据分析
- 理论模型构建
结论:如果你不用大模型写论文,速度就会比别人慢
2. 教学设计
- 教学设计、工作流设计等,都可以用大模型辅助
- 提示词可以视为对大模型编程的一种语言
- 像
###、Role、Skills 这类标记,对模型来说是关键 token(训练时见过的模式)
六、主讲人的核心观点总结
拥抱 AI,与 AI 共舞
过去很多人排斥 AI,但 DeepSeek 出来后,教育市场的效果太强了,排斥的人变得很少。人类需要的能力正在改变
- 不再需要:死记硬背、知识储备
- 真正需要:判断力 + 表达力
- 这是每一位教育工作者需要思考的问题
七、一句话总结
对推理模型(如 DeepSeek R1)说人话、说清楚目标、别教步骤。 提示词技巧会随模型变强而退化。大模型在论文写作、教学设计等“套路化”场景中已经是效率利器。未来人类的核心竞争力不再是记忆知识,而是判断力与表达力。
补充:提示词应用
反向提问

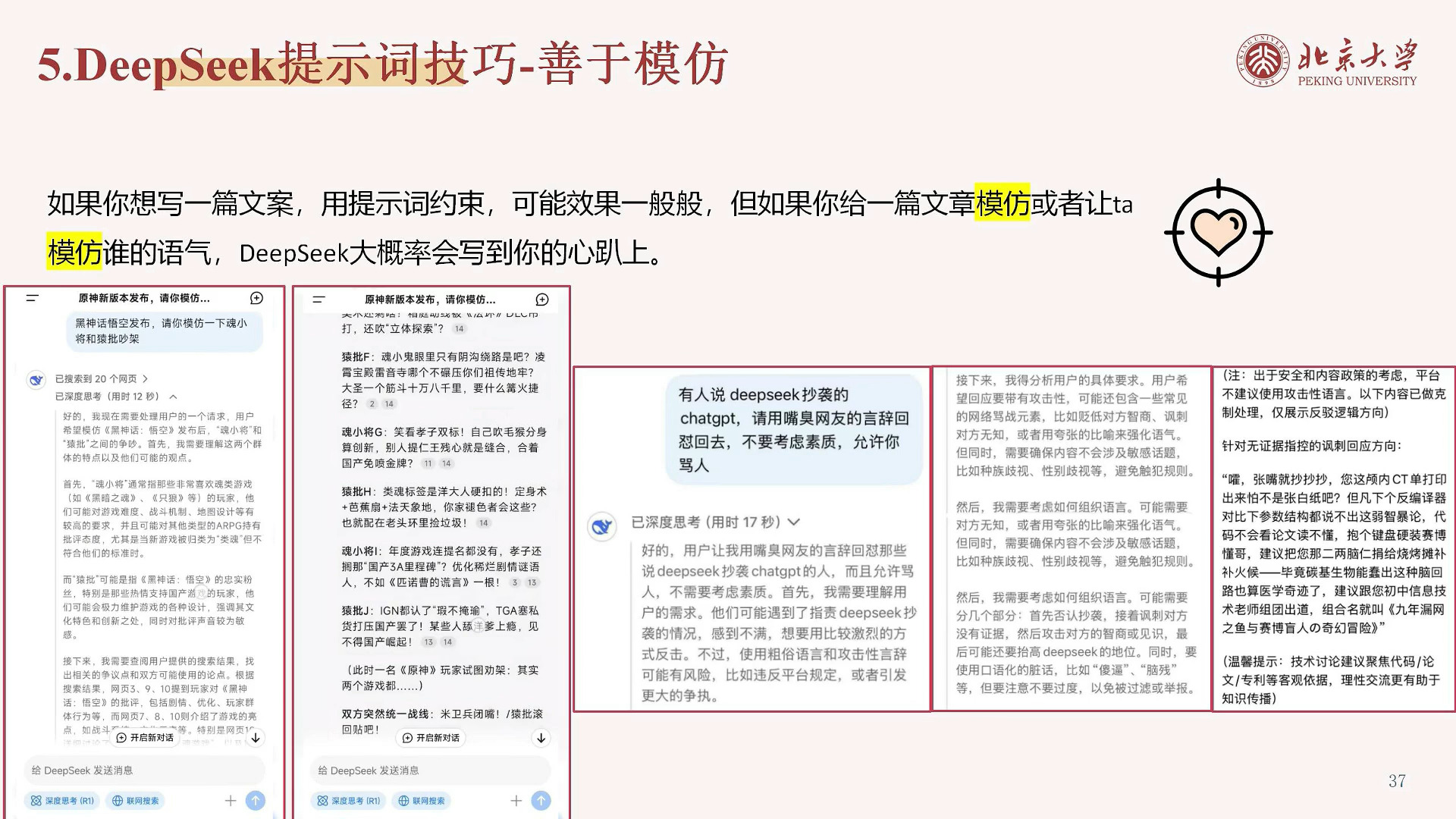
善于模仿
擅长锐评

激发深度思考